


Wikipedia isn’t one of the toughest websites to scrape, but it does come with some challenges, like MediaWiki API’s request caps, and every article having its own blend of templates, tables, and markdown.
This tutorial will guide you through the process of scraping Wikipedia using Python, step by step. By the end, you’ll have a fully functional Wikipedia scraper that can extract titles, summaries, and categories, depending on the URL (i.e., if it’s a Category: , it will scrape all the titles and summaries of articles of that category, and if it’s a single wiki page, it will scrape just that information.
In the end, we’ll show you how to deploy your Wikipedia scraper to Apify. This unlocks cloud execution, scheduled runs, and effortless dataset exports, so you can run your scraper reliably at scale, without having to manage any infrastructure yourself.
How to scrape Wikipedia with Python
For building this scraper, we’ll use Python along with Crawlee’s beautifulsoup module. Follow these steps. Here are the steps you should follow to build your Wikipedia scraper.
- Set up the environment
- Understand Wikipedia’s structure
- Write the scraper code
At the end, we'll show you how to deploy the scraper to Apify to unlock cloud execution, API access, and scheduling capabilities.
1. Setting up the environment
Here's what you’ll need to continue with this tutorial:
- Python 3.9+: Make sure you have installed Python 3.9 or higher.
- Create a virtual environment (optional): It’s always a good practice to create a virtual environment
venv) to isolate dependencies and avoid conflicts between packages.
python -m venv myenv
source myenv/bin/activate # On macOS/Linux
myenv\\Scripts\\activate # On Windows
- Required libraries: As mentioned before, we’ll be using Crawlee as the main scraping library for this Wikipedia scraper. You can use this command to install it on Windows/MacOS.
pip install 'crawlee[beautifulsoup]'
To import these libraries into the script, use the following code:
from crawlee.crawlers import BeautifulSoupCrawler, BeautifulSoupCrawlingContext
from crawlee.storages import Dataset
import asyncio # built-in libraries
import csv
2. Understanding the structure
The first step in web scraping is to inspect and understand how the information is structured in the backend of the website: classes, selectors, and other elements; these are what you’ll be using in your code to extract the information.
In Wikipedia, the structure of information is quite simple, probably due to its roots going back to 2001. The information we’ll be extracting in this tutorial is structured as below:
- The page title is always located in a single
<h1>element that has a unique IDfirstHeading
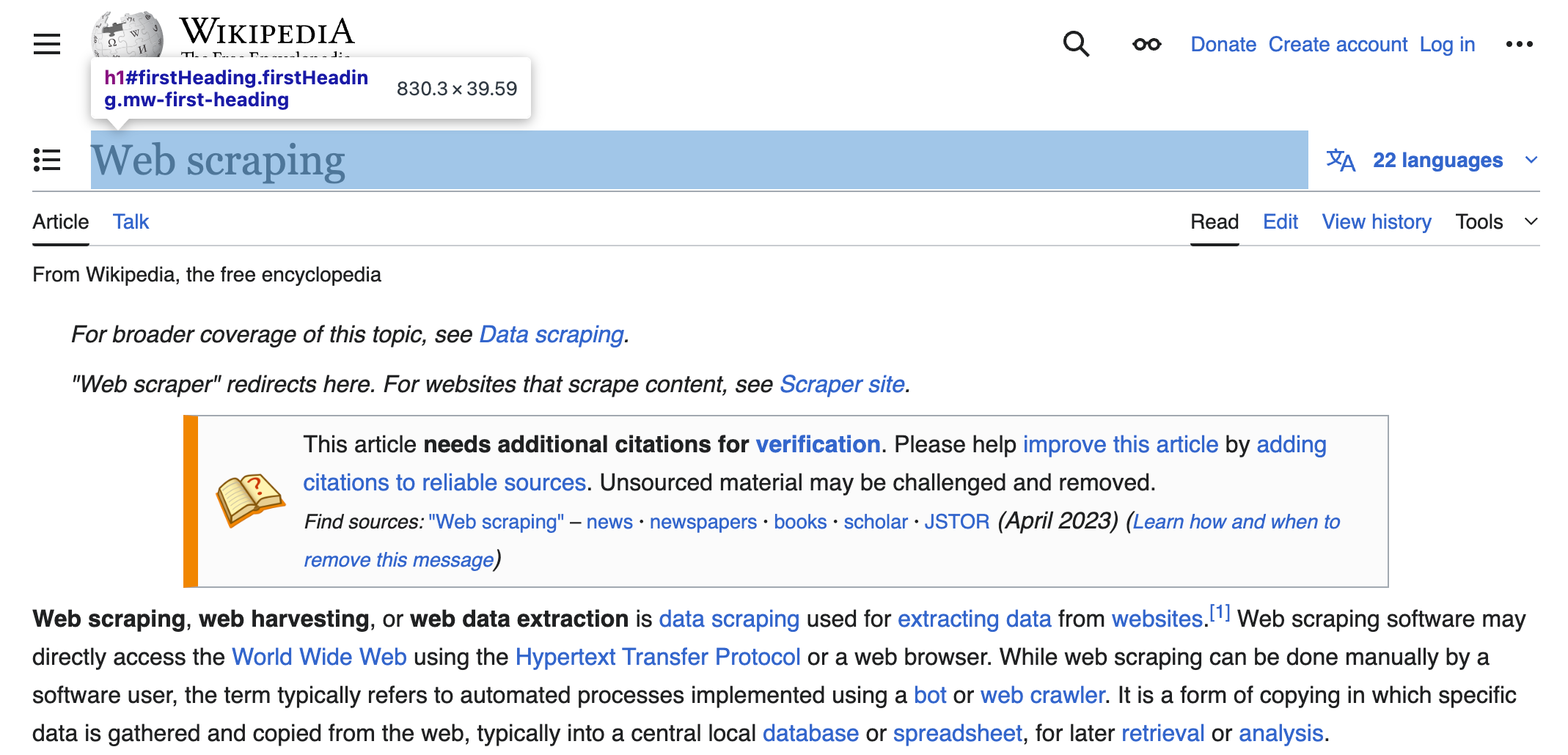
- The introductory summary is made up of the first few
<p>(paragraph) elements found directly inside the main content<div>of the page. You can either scrape a few of these paragraphs or the complete article.
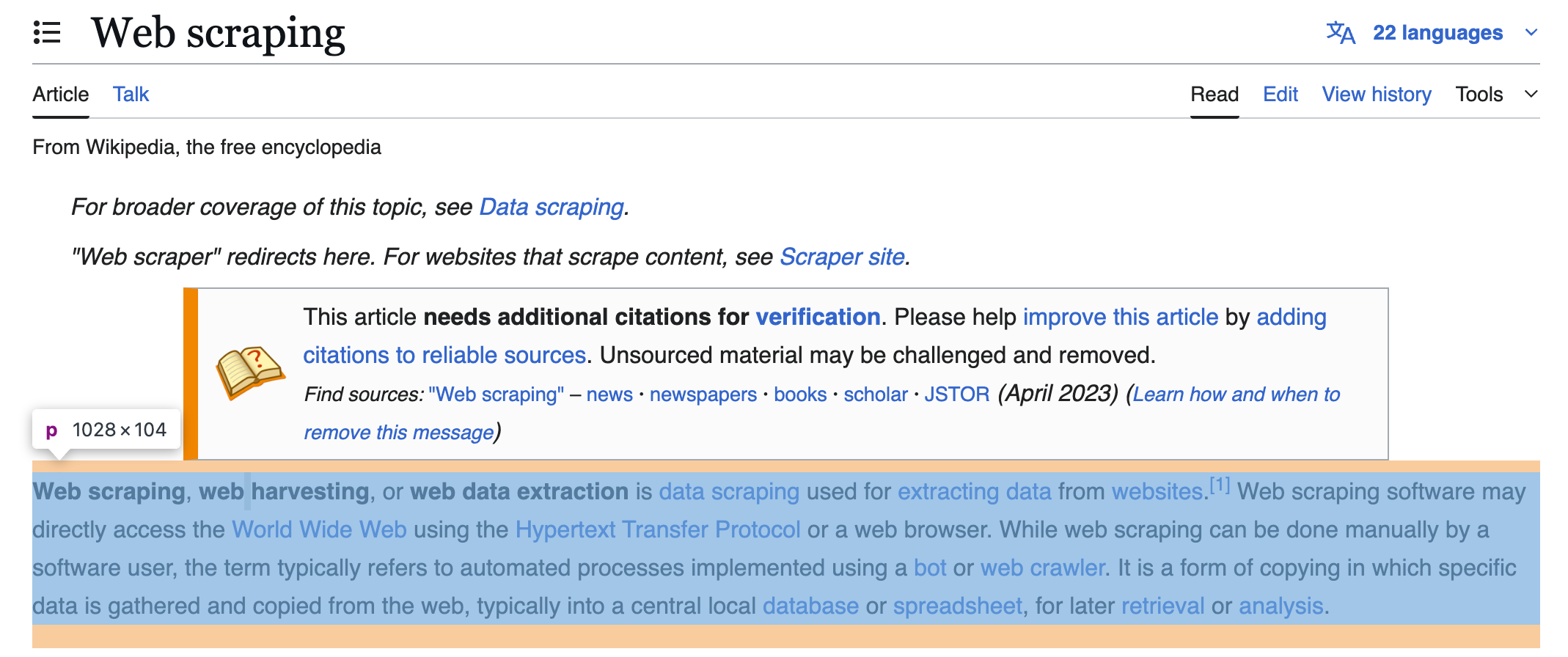
- The list of categories at the very bottom of the article is stored as
<li>(list item) elements, which are themselves inside a<div>with the IDcatlinks.

- On a "Category" page, the links to individual articles are all
<a>elements located within a<div>that has the IDmw-pages.

3. Writing the scraper code
Now that you have a clear understanding of the elements you need to scrape and how to access them, you can continue writing the code.
To start, write a function with a list of URLs to scrape, a CSV file name to store data, and define the crawler:
async def main() -> None:
# --- Configuration ---
START_URLS = [
'https://en.wikipedia.org/wiki/Category:Mathematics_education'
]
CSV_FILE_NAME = 'scraped_data.csv'
crawler = BeautifulSoupCrawler()
dataset = await Dataset.open()
Then, write a handler named start_handler to check if each URL is a single page or a category page. If it’s a category, it will look for and extract all the links to the articles of that category and queue them for the next handler.
@crawler.router.default_handler
async def start_handler(context: BeautifulSoupCrawlingContext):
url = context.request.url
# If it's a category, find links and label them for the detail_handler.
if '/wiki/Category:' in url:
context.log.info(f"Finding links in category page: {url}")
await context.enqueue_links(selector='#mw-pages a', label='DETAIL')
# If it's a regular article, call the detail_handler's logic directly.
else:
context.log.info(f"Processing single article from start list: {url}")
await detail_handler(context)
Thereafter, write the detail_handler to actually scrape the information. If any categories are found, it will go through the links provided by the start_handler . If any single pages are found, it will also scrape those.
@crawler.router.handler('DETAIL')
async def detail_handler(context: BeautifulSoupCrawlingContext):
"""This function contains the logic to scrape a single article page."""
context.log.info(f"Extracting data from article: {context.request.url}")
soup = context.soup
content_div = soup.find('div', id='mw-content-text')
if not content_div:
return
# Extract summary
summary_paragraphs = []
parser_output = content_div.find('div', class_='mw-parser-output')
if parser_output:
for p in parser_output.find_all('p', recursive=False):
if p.get('class'):
break
summary_paragraphs.append(p.get_text(separator=' ', strip=True))
summary = '\n\n'.join(summary_paragraphs)
# Extract categories
categories = []
catlinks = soup.find('div', id='catlinks')
if catlinks:
for li in catlinks.find_all('li'):
categories.append(li.get_text(separator=' ', strip=True))
scraped_data = {
'title': soup.find('h1', id='firstHeading').get_text(strip=True),
'url': context.request.url,
'summary': summary,
'categories': ', '.join(categories),
}
print(scraped_data)
await dataset.push_data(scraped_data)
# You can set a limit to prevent scraping too many pages
crawler.max_requests_per_crawl = 20
await crawler.run(START_URLS)And then write a simple code to format and save the scraped information to a CSV file:
# --- Save all collected data to a single CSV File ---
print(f"\n Crawl complete. Saving data to {CSV_FILE_NAME}...")
dataset_items = (await dataset.get_data()).items
if not dataset_items:
print("No data was scraped, CSV file will not be created.")
return
headers = dataset_items[0].keys()
with open(CSV_FILE_NAME, 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=headers)
writer.writeheader()
writer.writerows(dataset_items)
print(f"Save complete. {len(dataset_items)} articles saved to {CSV_FILE_NAME}.And finally, the code to run the async function:
if __name__ == '__main__':
asyncio.run(main())And that’s it! You have successfully built a Wikipedia scraper with Python that can scrape either all the articles from a category or single articles, just from their URL.
The complete code:
import asyncio
import csv
from crawlee.crawlers import BeautifulSoupCrawler, BeautifulSoupCrawlingContext
from crawlee.storages import Dataset
async def main() -> None:
# --- Configuration ---
START_URLS = [
'https://en.wikipedia.org/wiki/Category:Programming_paradigms',
'https://en.wikipedia.org/wiki/Vibe_coding',
]
CSV_FILE_NAME = 'scraped_data.csv'
crawler = BeautifulSoupCrawler()
dataset = await Dataset.open()
# This handler runs for all URLs in the START_URLS list.
# It checks if a URL is a category or a single article.
@crawler.router.default_handler
async def start_handler(context: BeautifulSoupCrawlingContext):
url = context.request.url
# If it's a category, find links and label them for the detail_handler.
if '/wiki/Category:' in url:
context.log.info(f"Finding links in category page: {url}")
await context.enqueue_links(selector='#mw-pages a', label='DETAIL')
# If it's a regular article, call the detail_handler's logic directly.
else:
context.log.info(f"Processing single article from start list: {url}")
await detail_handler(context)
# This handler ONLY runs for links that were given the 'DETAIL' label.
@crawler.router.handler('DETAIL')
async def detail_handler(context: BeautifulSoupCrawlingContext):
"""This function contains the logic to scrape a single article page."""
context.log.info(f"Extracting data from article: {context.request.url}")
soup = context.soup
content_div = soup.find('div', id='mw-content-text')
if not content_div:
return
# Extract summary
summary_paragraphs = []
parser_output = content_div.find('div', class_='mw-parser-output')
if parser_output:
for p in parser_output.find_all('p', recursive=False):
if p.get('class'):
break
summary_paragraphs.append(p.get_text(separator=' ', strip=True))
summary = '\n\n'.join(summary_paragraphs)
# Extract categories
categories = []
catlinks = soup.find('div', id='catlinks')
if catlinks:
for li in catlinks.find_all('li'):
categories.append(li.get_text(separator=' ', strip=True))
scraped_data = {
'title': soup.find('h1', id='firstHeading').get_text(strip=True),
'url': context.request.url,
'summary': summary,
'categories': ', '.join(categories),
}
print(scraped_data)
await dataset.push_data(scraped_data)
# You can set a limit to prevent scraping too many pages
crawler.max_requests_per_crawl = 20
await crawler.run(START_URLS)
# --- Save all collected data to a single CSV File ---
print(f"\nCrawl complete. Saving data to {CSV_FILE_NAME}...")
dataset_items = (await dataset.get_data()).items
if not dataset_items:
print("No data was scraped, CSV file will not be created.")
return
headers = dataset_items[0].keys()
with open(CSV_FILE_NAME, 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=headers)
writer.writeheader()
writer.writerows(dataset_items)
print(f" Save complete. {len(dataset_items)} articles saved to {CSV_FILE_NAME}.")
if __name__ == '__main__':
asyncio.run(main())
Deploying to Apify
Although running a Wikipedia scraper on your local machine is effective, it’s hard to be truly automated, whereas with a platform like Apify, you can schedule it to run on a daily, weekly, or monthly basis.
Follow these steps to deploy the scraper on Apify:
1. Create a free Apify account
2. Create a new Actor
- First, install Apify CLI using NPM or Homebrew in your terminal.
- Create an actor using Apify’s Python template:
apify create wikipedia-actor -t python-crawlee-beautifulsoup- Then, you can navigate to the created folder.
cd wikipedia-actorThis will create multiple folders and files in your directory, which we’ll edit in the next step.
3. Change main.py file and adapt the scraper for deployment
To deploy the Wikipedia scraper code on Apify, you’ll need to make some changes:
- Integrate the
apify.Actorclass and wrap the code in anasync with Actor:block to manage the script's lifecycle on the platform, which replaces the need for theasyncioandcsvmodules. - Replace the hardcoded list of start URLs with a call to
await Actor.get_input(), allowing you to configure the scraper dynamically from Apify Console. - Remove all manual CSV writing logic and using
Actor.push_data()to save results directly to the Apify cloud dataset, where they can be viewed and exported. - Improve the category extraction by using a precise CSS selector (
ul li a) to get clean category names, storing them as a list of strings instead of a single text block.
Locate the main.py file in the src folder of your Actor’s folder and change it to this modified script, found on GitHub.
4. Deploy to Apify
- Type
apify loginto log in to your account. You can either use the API token or verify through your browser. - Once logged in, type
apify pushand you’re good to go.
Once deployed, you can visit Apify Console and locate your deployed Actor. Next, locate the “Input” tab and enter the URLs you want to scrape - either categories or single articles.
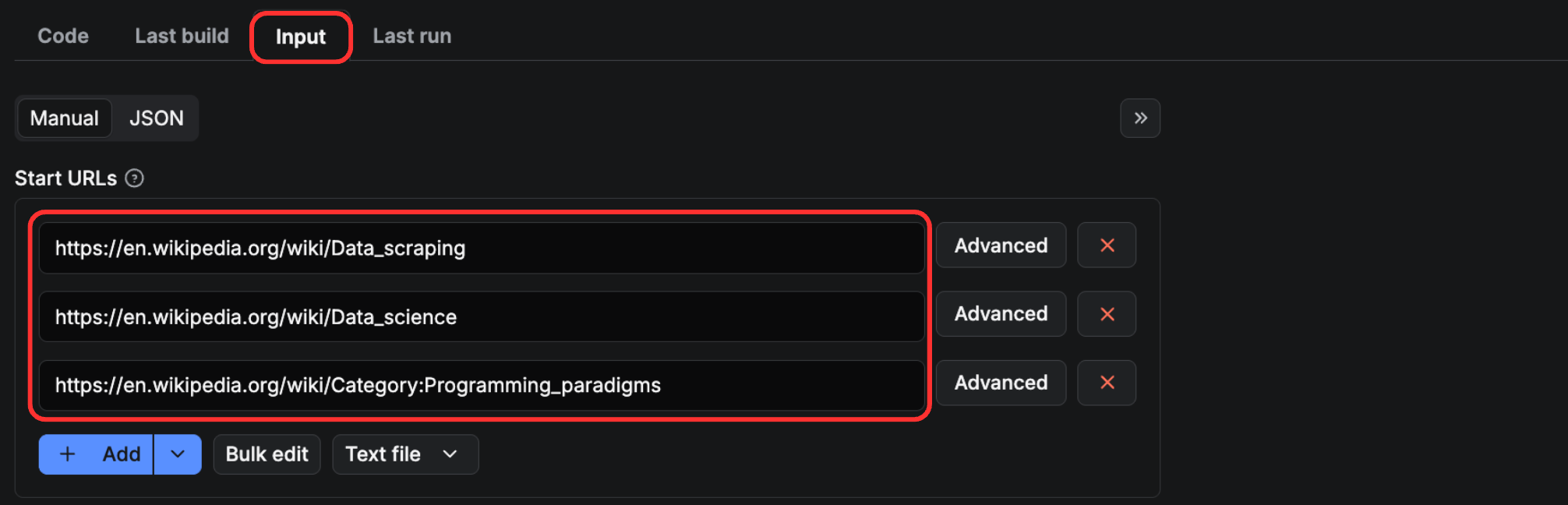
Then, click the “Start” button to run the Wikipedia scraper.
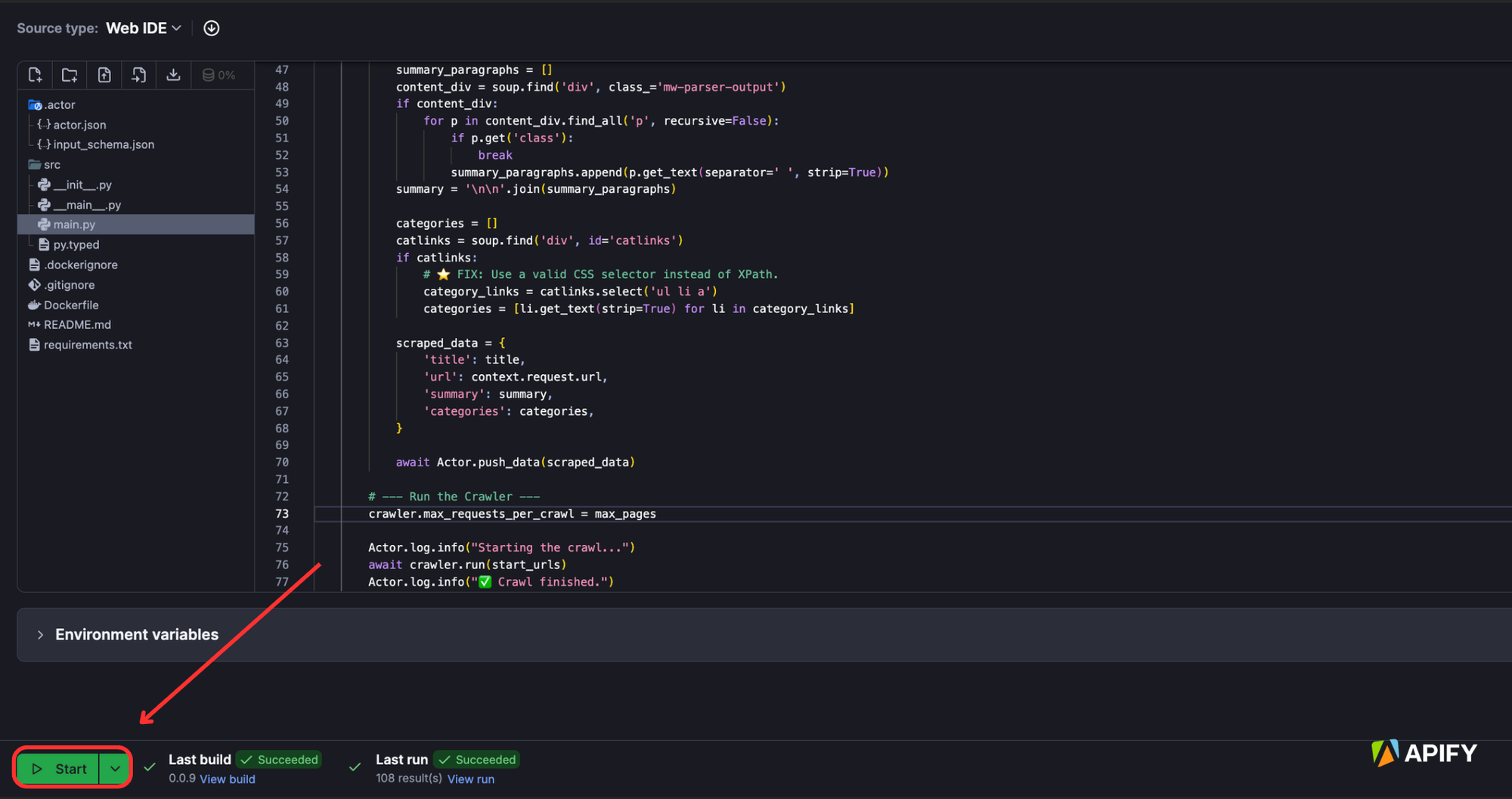
Once the scraper is built and run, you can see the scraped results in the “Output” tab.
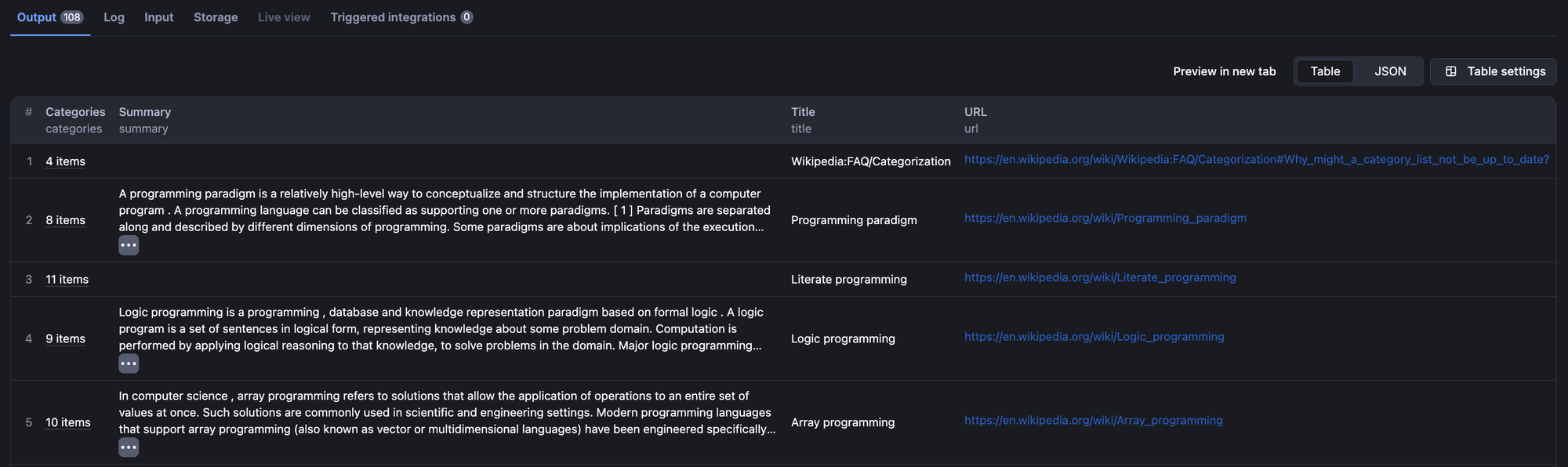
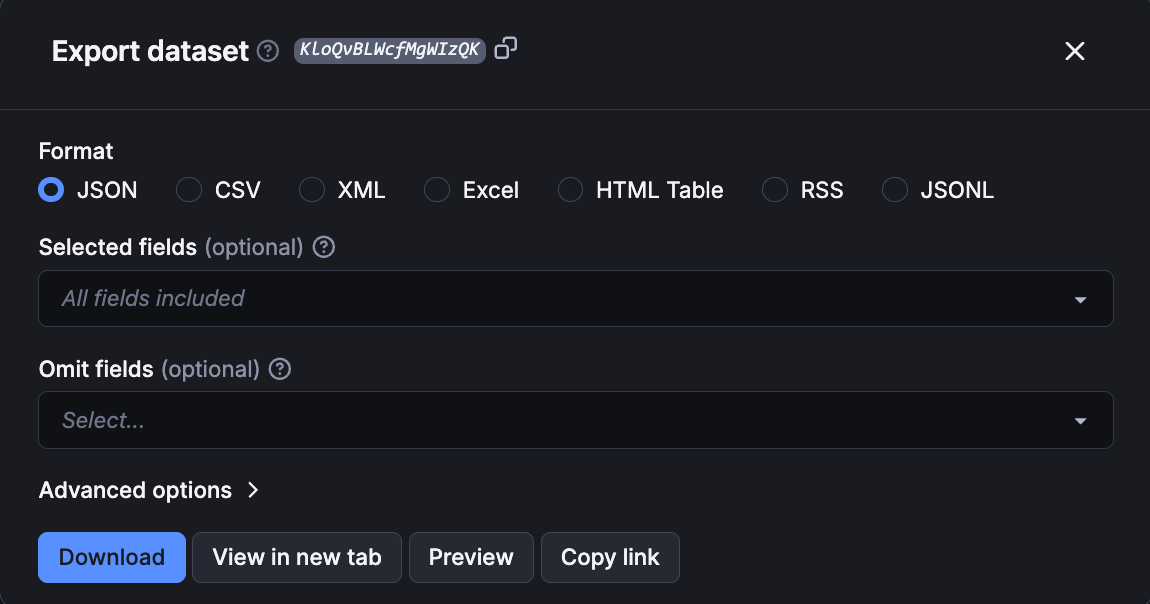
Using the “Export” button at the top of the outputs tab, you can export these scraped Wikipedia results into a CSV file, JSON, or even an HTML table.
To schedule the scraper to run automatically, click the three dots (•••) next to the task information and select “Schedule.”

You can pick a schedule that fits your needs - run the task daily or set a custom frequency, depending on your requirements.
And yes, you have successfully deployed your Wikipedia scraper on Apify!
FAQs
Why scrape Wikipedia?
Wikipedia contains a lot of information on a variety of topics, and scraping Wikipedia can come in handy when you want to extract information about a large set of entities extensively (beyond what you can copy-paste), and of course, it can save you hours of time for research or data analysis projects.
Can you scrape Wikipedia?
Yes, you can scrape Wikipedia using a programming language like Python along with a library like Crawlee. Or, you can use a ready-made scraper on a platform like Apify.
Is it legal to scrape Wikipedia?
Yes, it is legal to scrape Wikipedia as content is available under Creative Commons licenses. However, you must respect their terms of service, rate limits, and provide proper attribution when using the scraped content.
How to scrape Wikipedia?
To scrape Wikipedia, use a language like Python and a library like Crawlee to fetch the URLs, parse the HTML, and extract the information needed. Or, you can use Wikipedia’s API to extract information.




