Hey, we're Apify. You can build, deploy, share, and monitor your scrapers and crawlers on the Apify platform. Check us out.
Unfortunately, some of our users reported that they struggle to find information on how to use it because our API documentation was all over the place. Basically, each web page in our web app had a separate section documenting API endpoints corresponding to that page. Clearly, this wasn’t the best approach…
Today, we’re announcing a completely revamped API documentation and other major improvements to our API.
New features
- All API endpoints that return an array of elements now support pagination. For example, this enables users to access all historical crawler execution records.
- We added new endpoints to update and delete crawlers.
- Support for synchronous execution of crawlers, which enables API clients to wait up to 120 seconds for a crawler execution to finish. This feature greatly simplifies invocation of quick crawlers, without a need to use webhooks or active polling loops.
- Now it’s possible to set crawler cookies via the API, which can simplify passing login forms (see a knowledge base article on cookies and login forms)
- We activated API rate limiting to prevent misbehaved clients to slow down well-behaved clients.
New documentation
We rewrote our API documentation from scratch and put it on a new API Reference page. Each API endpoint is now fully documented, including a detailed description of HTTP request and response formats:
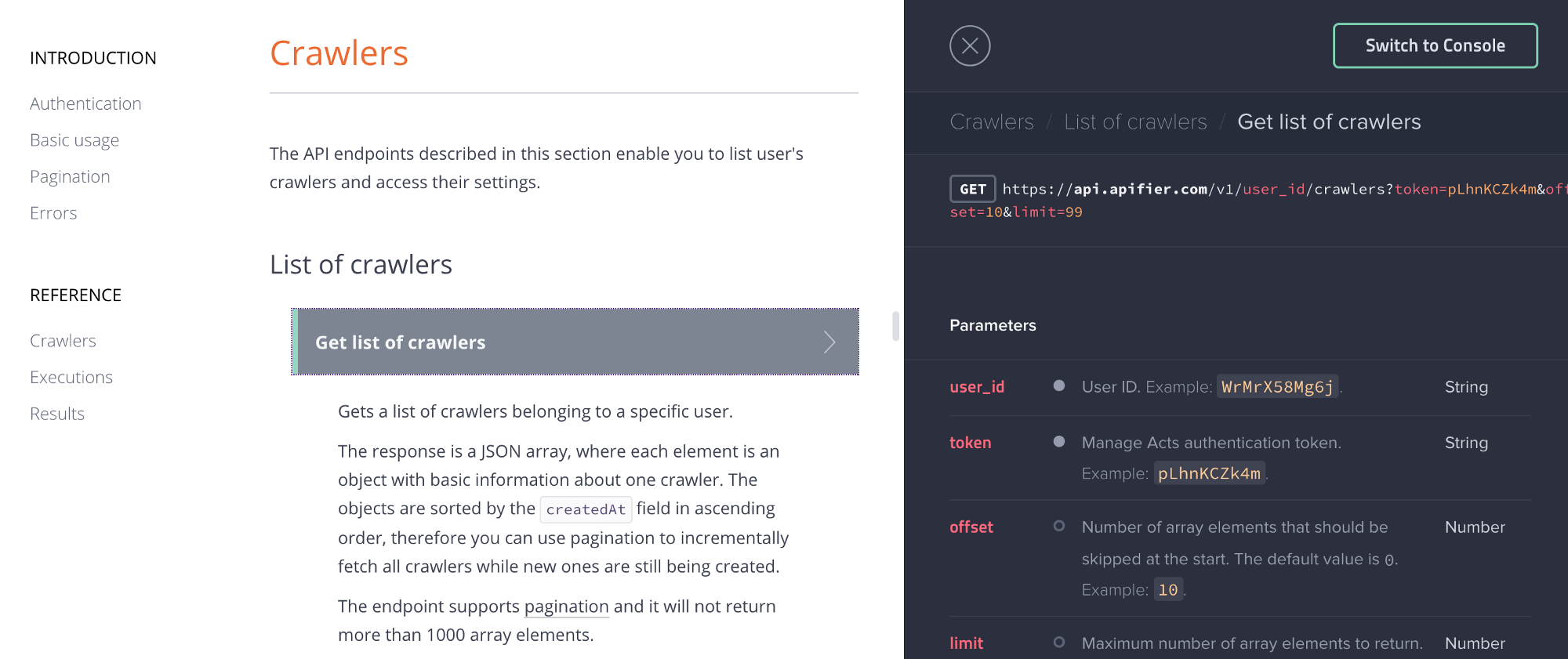
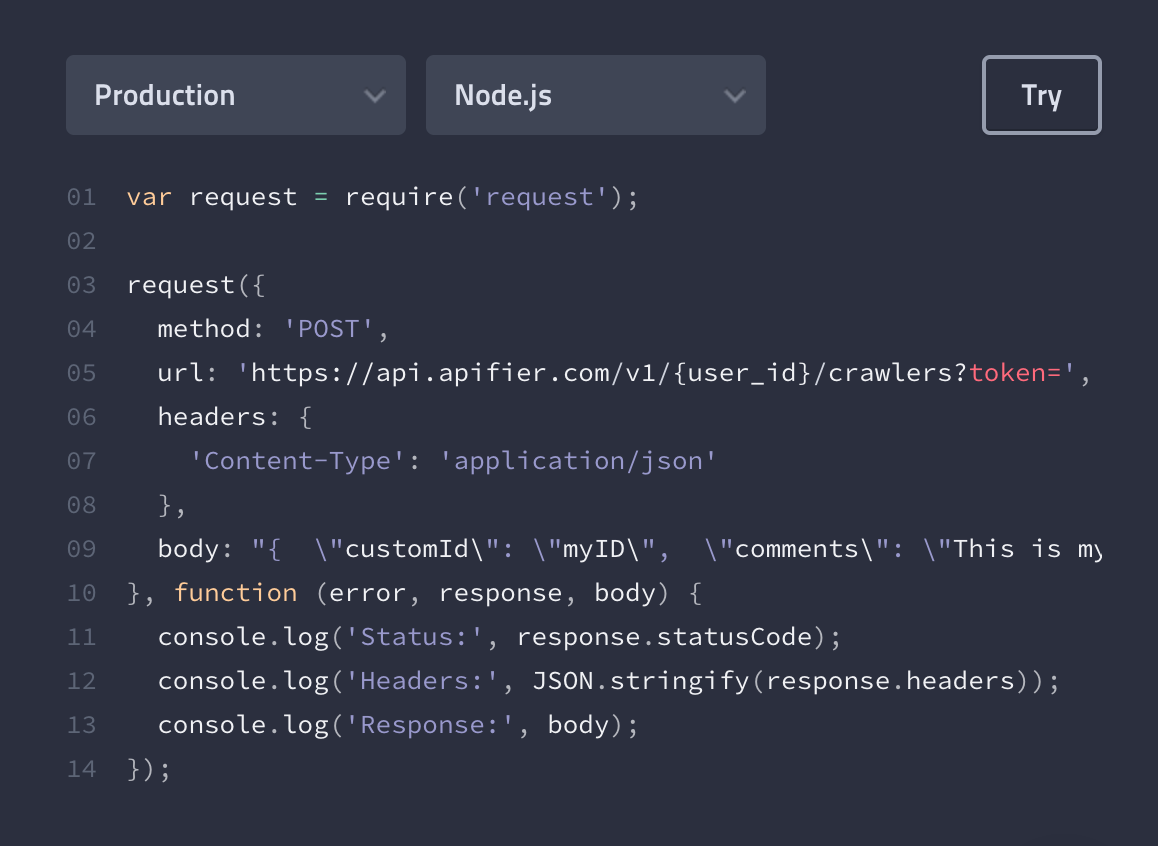
There are also working examples showing how to call each API endpoint from various programming languages.
The API documentation also provides a console that enables you to edit request parameters and headers, edit the payload and the HTTP request of each API endpoint against:
- Production system
- Mock server — it only returns dummy example responses
- Debugging proxy — it routes the HTTP requests through a proxy provided by Apiary, which enables their introspection
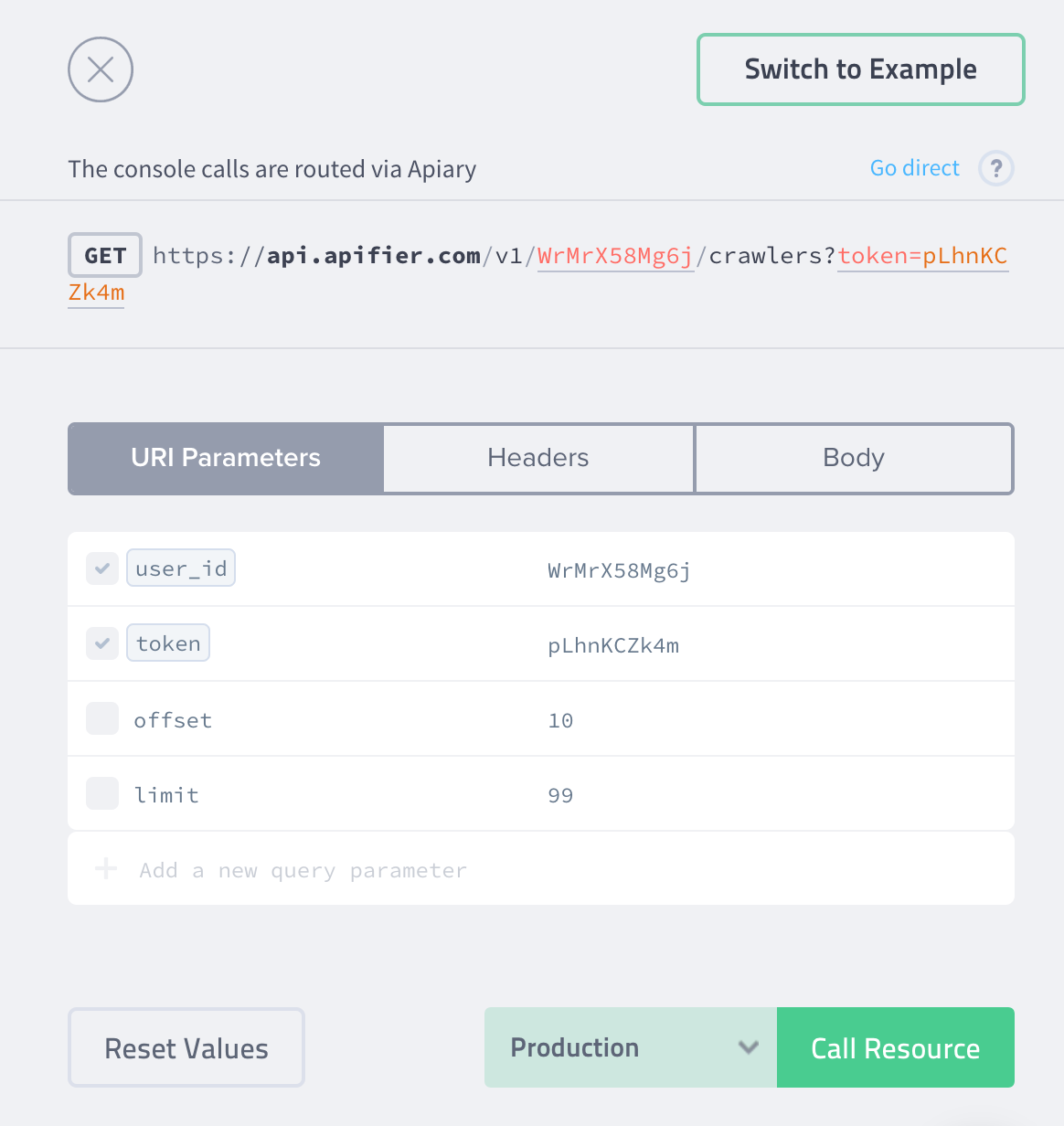
Note that all API endpoints described in the documentation reference a real user account that we use to run the demos on our home page. Therefore, you can live-test your API client against these endpoints, e.g. fetch the list of demo crawlers, view their settings, list their executions, etc. However, the API endpoints in the documentation only support read-only operations. For example, if you try to change crawler settings, you will receive an error.
Merry Christmas and happy crawling (or web scraping, as of 2023)!