


If your day involves tracking competitor prices, checking product availability, or keeping large catalogs synchronized across multiple e-commerce sites, you’ve probably tried using public APIs to collect that data. But APIs from platforms like Amazon, Walmart, and Shopify are designed for their own sellers and affiliates, not for competitive analysis. They typically expose only a fraction of the available product data: one primary offer price, limited stock status, and basic metadata, and omit essential details like multi-seller listings, variant pricing, regional availability, or historical changes.
So, many pricing, catalog, and analytics teams eventually turn to web scrapers. A well-built scraper can extract complete product and category data directly from live pages, capturing the same information a customer sees - including promotions, reviews, seller names, and dynamic pricing. Scrapers also bypass API restrictions and rate limits, so you can cover thousands of SKUs, monitor competitors across multiple domains, and feed that data directly into your pricing, catalog, or business-intelligence systems.
Below are five e-commerce scrapers that can do this reliably at scale:
- Apify
- DataWeave
- Bright Data
- Import.io
- Diffbot
These five tools make the list because each represents the best in its class. Apify leads for flexible, multi-site scraping at scale. DataWeave turns scraped data into pricing intelligence for retail teams. Bright Data provides the most reliable proxy and unblocking infrastructure. Import.io delivers managed, enterprise-grade data extraction with guaranteed uptime. Diffbot uses AI to turn web pages into structured product data instantly.
Together, they cover the full spectrum of e-commerce scraping - from raw collection to analysis and delivery.
1) Apify - E-commerce Scraping Tool
Best overall when you need multi-site, category + listing data in one pipeline
E-commerce Scraping Tool is designed for price/stock monitoring across multiple e-commerce sites (Amazon, Walmart, eBay, Etsy, Alibaba, and others). With this, you can build a unified, structured catalog for BI without maintaining scrapers for each site.
Why it tops the list
- You provide a mixed list of category and/or product URLs - from one or many different e-commerce sites - and the tool extracts them in the same execution. That’s the difference between one pipeline vs. juggling three. Result: one deduplicated export for analysis or pricing engines.
- It's purpose-built for e-commerce schemas (title, price, availability, brand, identifiers, images, seller, etc.), so downstream joins are predictable.
- It runs on Apify's managed cloud, providing detailed run statistics, alerting, conditional scheduling, storage, real-time webhooks, and configurable result retention to satisfy compliance audits or historical analyses.
- Apify autoscales compute instances, rotates datacenter or residential proxies by geography, and applies anti‑detection tactics such as browser‑fingerprint randomization, human‑like delays, and outsourced CAPTCHA solving.
- When a website changes - a common problem that kills ordinary scrapers - Apify’s team maintains and updates the tool, so your scheduled runs continue without you touching any code.
- Though Apify focuses on reliable data collection rather than analytics, its integrations let you automatically send scraped data into Google Sheets, AWS S3, Google Cloud Storage, or BI tools like Power BI, Tableau, and Looker, using built-in connectors or API/webhooks. This allows pricing, catalog, and analytics teams to visualize or model competitor data in the tools you already use.
If the tool (or any of the other e-commerce scrapers on Apify Store) doesn't meet your needs (niche platforms, ERP handoffs, MAP workflows), Apify’s Professional Services can build and maintain a custom solution for you.

2) DataWeave
A great option when the end goal is pricing intelligence (not raw scraping)
Though DataWeave is less flexible if you want to scrape arbitrary sites or fields outside its supported pricing/assortment coverage, it's great when your deliverable is pricing strategy and dashboards, rather than a general multi-site data lake.
Why it's on the list
- DataWeave focuses on pricing teams. It automates competitive data collection and layering analytics such as price positions, promo insights, and assortment visibility so the output is decision-ready, not just a CSV.
- It emphasizes product matching and accuracy as part of its solution stack, a critical step many basic scrapers leave to you.
3) Bright Data - Datasets + Web Unlocker
A solid choice when unblocking and geography are the real bottlenecks
Bright Data is all about infrastructure, but it's not a turn-key multi-site scraper. You’ll still build and maintain extraction logic (unless a purchased dataset meets your needs).
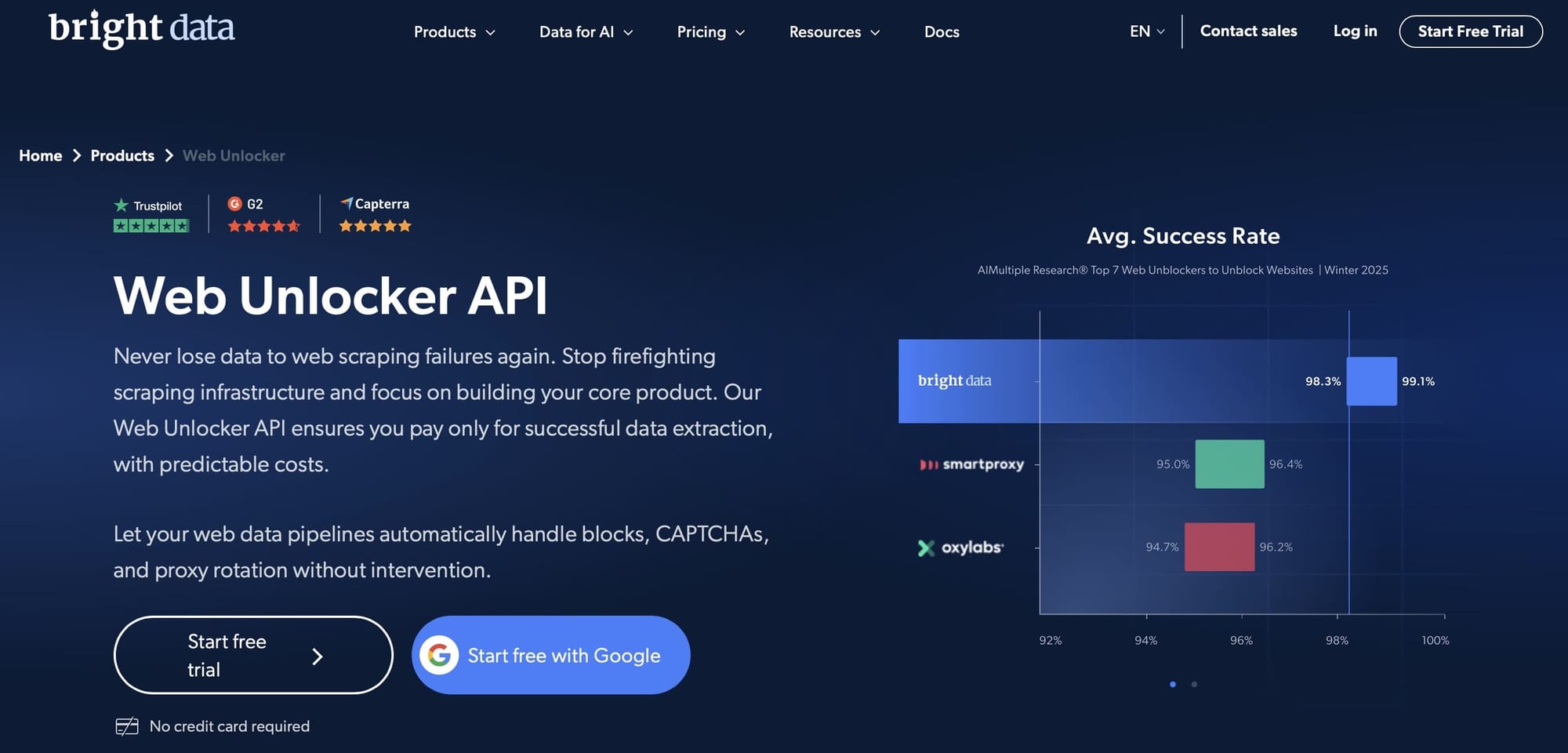
Why it's on the list
- Bright Data’s Web Unlocker automates IP rotation, fingerprinting, CAPTCHA solving, and retries so your scrapers can access pages that would otherwise block you.
- For popular e-commerce sources, you can buy ready-made datasets (Amazon, Walmart, Zara, etc.). This is often the fastest route to baseline coverage when you can accept a provider’s schema/freshness cadence.
4) Import.io
A good option when you want managed enterprise extraction
Import.io offers reliable, managed data delivery, but that stability comes with a higher cost and less flexibility for hands-on changes. It’s a strong contender when you want outcomes without custom tinkering.

Why it's on the list
- It offers apps + APIs + expert services to run large crawling programs with scheduling, QA, and delivery built in. If your team wants outcomes but not to staff a scraping squad, Import.io reduces operational risk.
- What you can do in the UI you can typically automate via API/webhooks - useful for pushing data into BI/ML pipelines.
5) Diffbot
A solid choice when you need structured product data via API without writing selectors
Diffbot is a good option for rapid breadth or when you can’t invest in per-site selectors. You get less control over edge-case fields vs. owning your selectors, and cost can climb at high volumes compared with running your own extraction pipeline. Still, it's a strong contender for category-wide coverage without hand-curating URLs.
Why it's on the list
- Send Diffbot a product URL, and it returns a structured JSON with the typical product attributes (title, price, images, brand, etc.).
- With its Crawlbot, you can discover product pages across a domain and apply extraction at scale.
Best e-commerce scrapers comparison
| Tool | Core use case | Multi-site capability | Maintenance responsibility | How it delivers data | Key strength | Primary limitation |
|---|---|---|---|---|---|---|
| Apify E-commerce Scraping Tool | Multi-site product + category extraction | ✅ Yes – many domains in one run | Apify-managed platform | API, webhooks, CSV, JSON, DB export | Reliable, configurable multi-site scraping; no coding required | Focuses on data collection, not analytics |
| DataWeave | Competitive pricing intelligence | ✅ Across supported retailers | Vendor-managed service | Dashboards, APIs | Converts scraped data into pricing insights | Limited to predefined retailer coverage |
| Import.io | Enterprise-managed data extraction | ✅ Multi-domain via managed projects | Vendor-managed service | API, CSV, DB | SLA-based managed extraction for enterprises | You receive raw data only |
| Bright Data | Scraping infrastructure / unblocking | ✅ Global coverage | User-managed (proxies/datasets) | Raw data, datasets | Industry-leading proxy and unblocking reliability | You build and maintain scraper logic |
| Diffbot | AI-structured product data via API | ✅ Web-wide | Fully automated API | JSON API | Instant structured data without writing selectors | Per-URL pricing can become costly |
The #1 solution for e-commerce
Apify’s E-commerce Scraping Tool is the best option when you want one pipeline that can grab categories and product listings across many sites in a single run, scale to large catalogs, and deliver clean data to your systems - without orchestrating three different tools.
And if you need something specialized, Apify’s Professional Services team can spec, build, and maintain custom scrapers for niche sites, multi-region dedupe, or ERP integrations.
Note: This evaluation is based on our understanding of information available to us as of March 2026. Readers should conduct their own research for detailed comparisons. Product names, logos, and brands are used for identification only and remain the property of their respective owners. Their use does not imply affiliation or endorsement.




