


In this blog post, we’ll explain why we are retiring Apify Crawler, what it means for you and how you can migrate your crawlers to the new Actor
To simplify the migration of your crawlers to the new Actor, we’ve built a Crawler migration tool, which is described in detail below. In most cases, the migration should only take a few minutes of your time and can be done with a few clicks. However, if you’re using webhooks, API, Zapier or Integromat, you might need to update your integration. Before you launch the migration tool, make sure to read this blog post to understand all the implications of migration.
Note that, for new projects, we recommend using the Web Scraper (apify/web-scraper) actor, our new flagship web scraping and crawling tool based on the modern Headless Chrome web browser.

Why are we doing this?
When we launched Apify in 2015, there was only one product, our Crawler. It worked well for lots of web scraping use cases, but its simple design meant that it could never handle more complex scenarios, enable custom integrations, or use external APIs. That’s why in 2017 we launched Apify Actors, a general-purpose serverless computing platform for long-running data extraction and web automation jobs called actors.
Over time, we’ve greatly enhanced the capabilities of the Apify Actors platform. For example, we released the Apify SDK to simplify the development of actors, launched various specialized storage types, added features to automatically generate a user interface for actors, and more. The goal of all these features was to gradually provide our users with tools that would replace all the capabilities of the legacy Crawler, but that could be used as independent components.
We have now reached the stage where the Apify Actors platform can completely replace the legacy Crawler — feature for feature. This has allowed us to release a new actor called apify/legacy-phantomjs-crawler, which provides the complete functionality of the legacy Crawler, accepts the same input configuration and has the same format for its results.
By the way, this means we’ve just open-sourced Apify Crawler — the source code is on GitHub!
In order to avoid confusion for our users with two overlapping products, and to help us ship new features faster by removing redundant code from our codebase, we’ve decided to completely shut down the legacy Apify Crawler.
Although we have tried to make the migration from the legacy Crawler to Apify Actors as simple as possible, we realize that this change might be inconvenient for you. Please note that we carefully analyzed the pros and cons of making this change, and ultimately decided that, in the long term, it was in the best interests of our users and customers to retire the Crawler.
The new actors will let you enjoy a much larger set of features, including:
- No more limits on the number of parallel crawling processes
- Ability to use multiple webhooks, to have webhooks for certain events (e.g. crawling failed) and to define a custom payload for webhook requests
- Fairer pricing that will bring significant savings when crawling efficiently
- Persistent logs from your jobs
- More flexible API to retrieve results (new parameters allow you to pick only certain fields or omit some fields from results)
- Easy way to orchestrate your crawlers with actors from Apify Store; for example, to receive an email when your job has failed.
Will the change boost performance?
We believe that your crawlers will run faster and more efficiently after migration. Performance in the old Apify Crawler could only be controlled by the Parallel crawling processes setting, whose maximum value was limited by your subscription plan. With Apify Actors, there is no such limit, and the performance of actors is determined by the amount of memory that you set for them. The new apify/legacy-phantomjs-crawler actor automatically scales the number of parallel crawling processes to use all available memory and CPU, providing you with the best possible performance.
The crawler migration tool (described below) automatically sets the memory of the newly created tasks so that the performance of the new tasks matches the performance of your old crawlers. However, if you notice that your crawlers are running slower after the migration, please try to increase the memory in task settings. Note that you can still limit the maximum number of parallel crawling processes using the Max parallel processes actor setting.
Additionally, the actor has several settings that might help improve the performance of your crawling jobs:
- You can uncheck the Download HTML images and Download CSS files settings to reduce the bandwidth and amount of time the crawler spends waiting for content.
- You can narrow down the Clickable elements CSS selector to select only the necessary elements that lead to new pages. By skipping unnecessary clicks, your crawler will run faster.
- Optionally, try to check the Don’t load frames and IFRAMEs setting, to skip loading frames and thus improve the speed of your crawler.
How will this affect pricing?
The legacy Crawler was billed based on the number of web pages crawled, without taking into account the complexity of the web pages. This meant that users who crawled simple websites or spent time to optimize their crawlers were paying the same price as users crawling the most complicated memory- and CPU-intensive websites. That wasn’t fair.
Apify Actors, on the other hand, are billed based on the exact amount of computation resources they consume. This amount is measured in so-called compute units. An actor running with 1GB of memory for one hour consumes one compute unit. The more memory you give to your actor tasks the faster they will run, but they will also consume more compute units.
After you migrate your crawlers to actor tasks, they will start consuming compute units. Each pricing plan comes with an amount of compute units that should be sufficient to download the same number of web pages as the old Crawler. This means that you should not need to upgrade your subscription plan in any way. However, if you notice that compute units are being consumed faster than crawler pages used to be, or you’re already using computing units of your plan for other jobs, please contact support@apify.com and we’ll figure something out.
Timeline for the changeover
June 18, 2019: Initial announcement
September 30, 2019: Deadline for users to migrate their crawlers
October 1, 2019: All remaining unmigrated crawlers will be automatically migrated to actor tasks and schedules. However, the schedules will not be enabled and thus periodic crawling jobs will stop running. We’ll notify all affected users.
October 2, 2019: Apify Crawler will stop working and it will no longer be possible to run crawlers in the app, using scheduler or API. Crawlers will still be accessible in the app and API in the read-only mode, but you will not be able to update them or run them. Crawling results will be available as usual, subject to the user’s data retention period.
October 31, 2019: The crawlers will be completely removed from the app and API and results will be no longer available.
Contact us if you have any questions!
If you have any questions about the migration or need any help with it, please contact support@apify.com. For bug reports or feature requests for the new apify/legacy-phantomjs-crawler actor, you can submit an issue on GitHub.
Technical guide to migrating your crawlers
We’ve prepared a number of more detailed articles on our knowledge base to make the process of migration go smoothly, you’ll find the relevant links in the following text. Read on for an overview of the technical aspects of the change.
Migration from crawlers to actor tasks
The new apify/legacy-phantomjs-crawler actor provides the same functionality, configuration options and results as the old Apify Crawler product. The best way to save and reuse the configuration of your crawlers is to create tasks for the new actor. In other words, instead of the old crawlers, you’ll be working with tasks in the Apify app and in the API.
To make this simple, we created a Crawler migration tool that automatically converts your crawlers to actor tasks. The tool is described in detail below. However, before you use it, please read the following sections so that you understand all the implications of migration.
Schedules
If you’re using schedules to run your crawlers at regular times, with the Crawler migration tool you can easily add the new actor tasks to the same schedules and remove the old crawlers from the schedule. This will ensure uninterrupted execution of your crawling jobs.
API
All aspects of the legacy Apify Crawler product can be programmatically managed using Apify API version 1, while Apify Actors are managed using Apify API version 2. Therefore, after migrating your crawlers to actor tasks, you’ll no longer be able to use API version 1 to manage your crawlers or download their results. Eventually, API version 1 will be shut down altogether — check the Timeline above for milestones and the migration deadline.
Before you migrate your crawlers to actor tasks using the Crawler migration tool, please update and test your API integration to work with Apify API version 2. We made a huge effort to make the new API as compatible as possible, so in most cases, the update will only require the replacement of several API endpoints.
For full details, see Mapping of API endpoints from version 1 to version 2.
Webhooks
If you’re using webhooks to get a notification when your crawlers finish, you’ll need to update the webhook handlers on your server to handle the new webhook payload format and update your integration to use Apify API version 2 instead of version 1 to download the crawling results (see the API section above).
The legacy Crawler used the following webhook POST payload format:
{
"_id": "<ID of the crawler execution>",
"actId": "<ID of your crawler>",
"data": "<Your custom finish webhook data>"
}The new apify/legacy-phantomjs-crawler actor invokes webhooks with the following POST payload format:
{
"actorId": "<ID of the apify/legacy-phantomjs-crawler actor>",
"taskId": "<ID of your actor task>",
"runId": "<ID of the actor run>",
"datasetId": "<ID of the dataset with crawling results>",
"data": "<Your custom finish webhook data>"
}Note that the migration tool will automatically migrate the webhook settings from your old crawlers to the new actor tasks, so you don’t need to make any changes in the actor task configuration. However, you’ll need to update your webhook endpoints to correctly handle the new payload format.
Zapier integration
We’ve launched a new Apify app on Zapier that works with actors and tasks instead of crawlers. So after you migrate your crawlers to tasks, you’ll need to manually update your existing zaps to use the new app.
For details, please read about migration of Zapier integration from legacy crawlers to the actor tasks in our knowledge base.
Integromat integration
We’re working on a new Apify app on Integromat that will work with actors and tasks. The new app will be ready in a few weeks, please stay tuned.
Code incompatibilities
Although we tried to make the new apify/legacy-phantomjs-crawler actor perfectly compatible with the old Crawler on the code level, there are a few minor changes in the parameters of the Page function. For more details, please see Compatibility with the legacy Apify Crawler.
Public crawlers
As part of the Crawler retirement, we’ll also be removing published crawlers from Apify Store. Since crawlers are being replaced by the tasks of the new apify/legacy-phantomjs-crawler actor, you might wonder whether it will be possible to publish the tasks instead. The answer is: sort of. Instead of publishing tasks, you can create a new unique actor from your task using the actor metamorph feature and publish the actor instead. To learn how to do this, please read about converting a task to an actor and publishing it on Apify Store in our knowledge base.
Note that we’ll automatically publish the most popular and still functional public crawlers this way, so you probably don’t need to do anything.
Crawler migration tool
Once you read the above sections and understand all the implications of migration from Crawler to Actors, we recommend you use the Crawler migration tool to automatically convert all your crawlers to actor tasks and update your schedules.
You can either migrate crawlers one-by-one or use a button that migrates all your crawlers automatically.
To trigger the migration of a single crawler, press the Migrate crawler to actor task button on the crawler detail page:
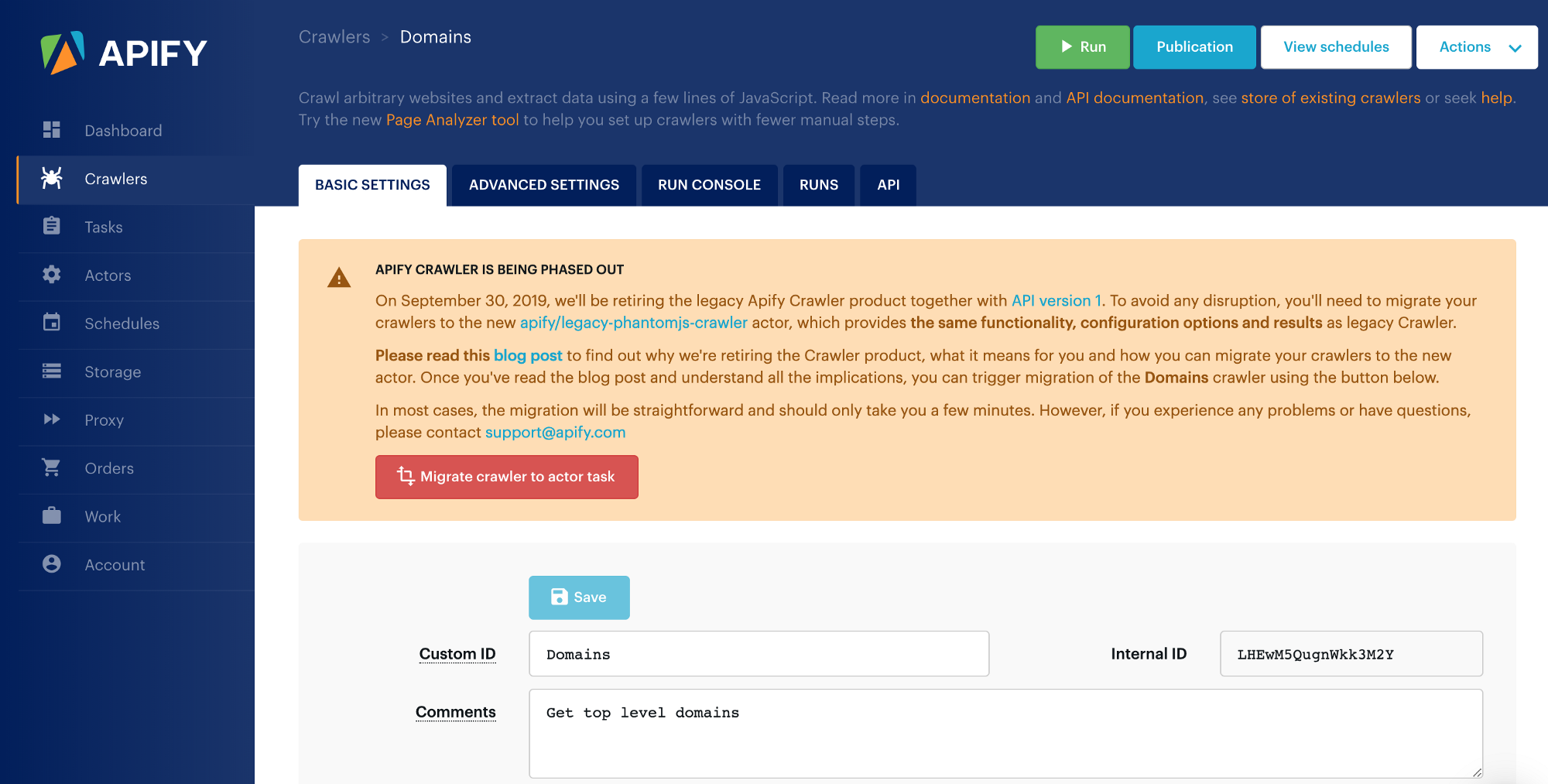
After you click the button and confirm your action, the system will automatically create a new task for your crawler, with the same configuration. Moreover, it will ask you whether it can update your schedules to run the new task instead of the crawler, and remove the crawler from the schedules to avoid duplicate execution if you choose so.
You can also perform a batch migration of all your crawlers that haven’t been migrated yet using the Migrate all actors or Migrate remaining crawlers button on the list of your crawlers:
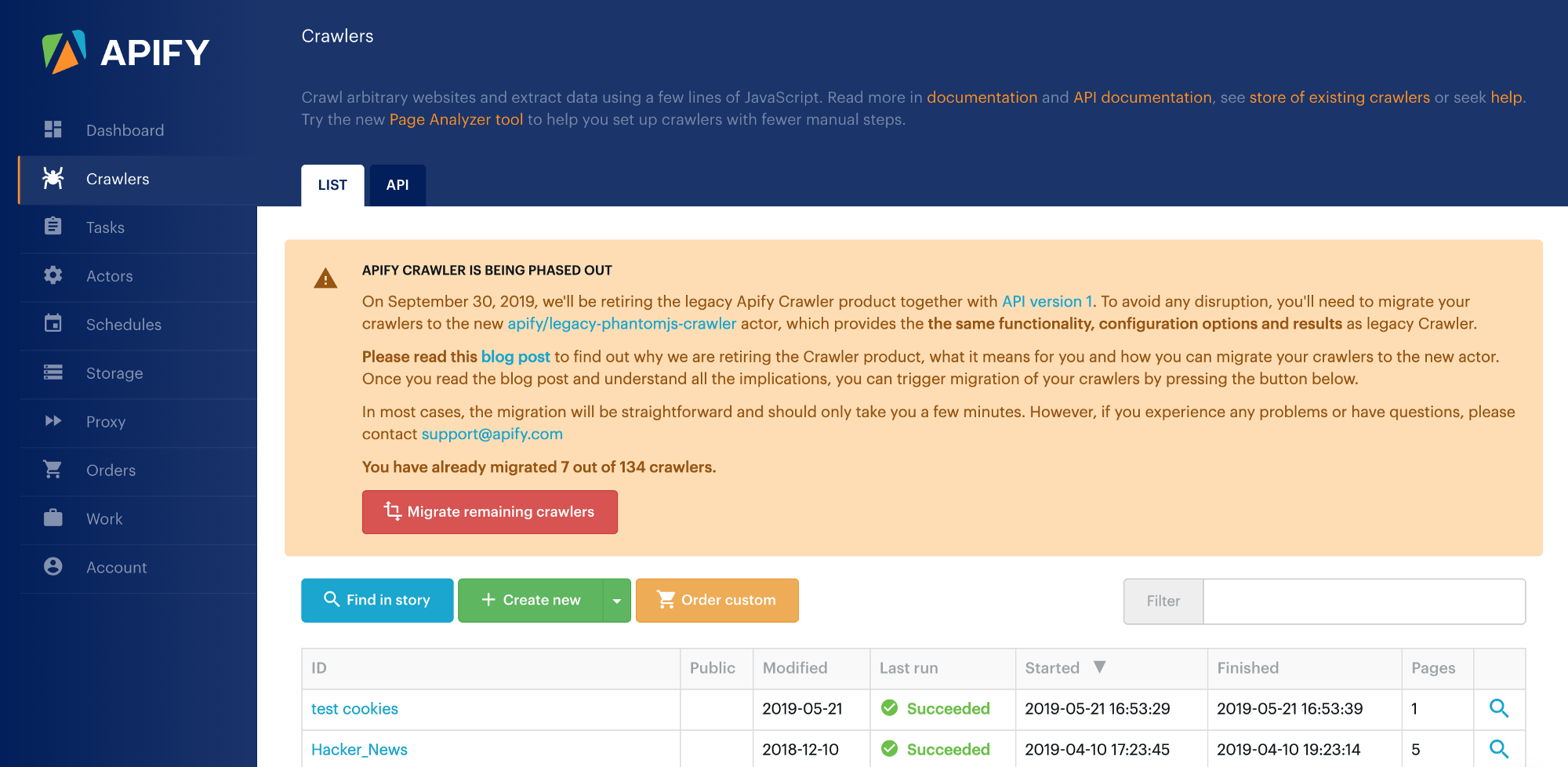
This action will create a new actor task for each of your crawlers.
Contact us for help
Again, we understand that this change might be confusing for some users, so if you have any questions about the migration or need any help with it, please contact support@apify.com





