We’re excited to introduce Actor Standby, a new feature to help you use Apify Actors with a request-response model as real-time APIs.
Traditional Actors are designed to run a single task and then stop. They're mostly intended for batch jobs, such as when you need to perform a large scraping or data processing task.
However, in some applications, waiting for an Actor to start every time is not an option. Actor Standby mode solves this problem by letting you have the Actor ready in the background, waiting for incoming HTTP requests. In a sense, the Actor behaves like a real-time web server or standard API server.
Use cases
Actor Standby is perfect for scenarios where rapid response times are essential. Some examples include:
- Real-time data processing: when you need to process data in real-time, having Actors on standby ensures there are no delays.
- Event-driven automation: for tasks triggered by specific events, standby Actors can handle the load immediately, ensuring timely execution.
- High-frequency scraping: if your scraping tasks require frequent execution, keeping your scraping Actors on standby minimizes downtime and maximizes throughput.
Using Standby Actors
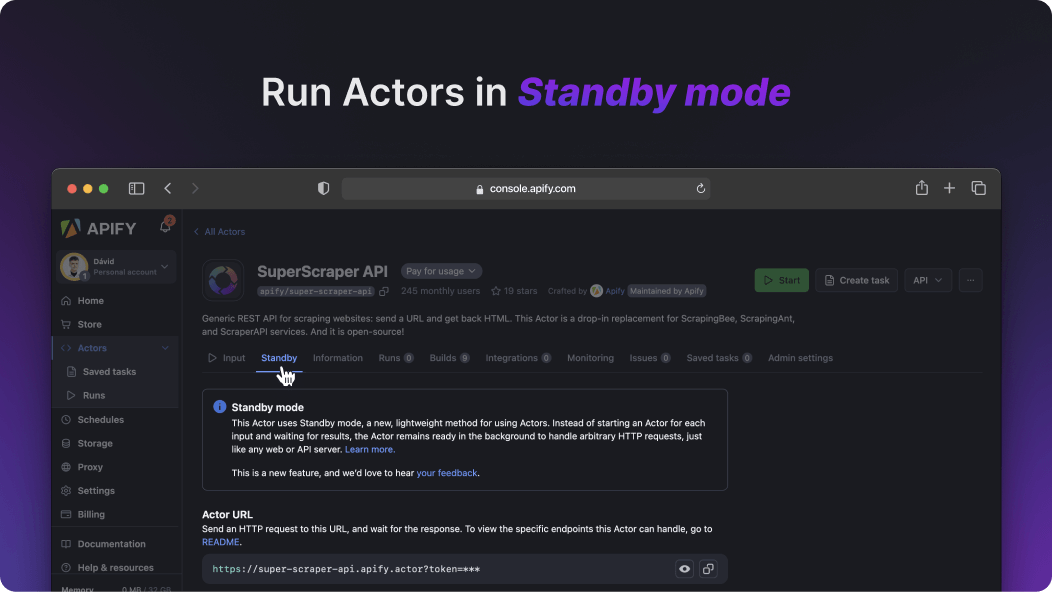
Some Actors already have Actor Standby enabled, such as our Super Scraper API. To use them, you can send HTTP requests to the Actor’s Standby URL, such as https://super-scraper-api.apify.actor/, and immediately get responses based on the request parameters and body that you send. It’s that simple!
Example of scraping the Apify Blog to extract article titles and links using the Super Scraper API:
> curl -g \\
'<https://super-scraper-api.apify.actor/?url=https://blog.apify.com&extract_rules={"articles":{"selector":".post-title>a","type":"list","output":{"title":"a","link":"a@href"}>}}'
--header 'Authorization: Bearer <YOUR_APIFY_API_TOKEN>'
{
"articles": [{
"title": "Introducing Apify Power Actors: do more by combining Actors into workflows",
"link": "/apify-power-actors/"
},
{
"title": "Oxylabs vs. Bright Data (for web scraping)",
"link": "/oxylabs-vs-bright-data/"
},
...
{
"title": "How to use Cloudscraper in Python for web scraping",
"link": "/cloudscraper/"
}]
}
How Actor Standby works
When you enable Actor Standby for an Actor, the Apify platform maintains a pre-warmed instance of that Actor. This instance is kept alive and ready to handle tasks immediately upon request. The platform manages the lifecycle of these standby instances, making sure they are always available when needed, without you having to worry about the underlying infrastructure.
In case of a high load on the Actor, the Apify platform automatically starts multiple instances of the Actor and routes requests between the multiple instances intelligently, to enable faster handling of these requests. When the load gets low again, the platform downscales the number of running instances, to keep the costs down.
Developing Standby Actors
To create a new Actor using Actor Standby, you can start from one of our own Actor Standby templates for JavaScript, TypeScript, or Python.
Then, you can just start listening and responding to requests on a pre-configured port. For example, in JavaScript, you can start a simple Actor Standby server like this:
import http from 'http';
import { Actor } from 'apify';
await Actor.init();
const server = http.createServer((req, res) => {
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('Hello from Actor Standby!\n');
});
server.listen(Actor.config.get('standbyPort'));
Get started with Actor Standby today
Actor Standby is now available on the Apify platform. Start using it today to make your workflows faster.
If you have any feedback on Actor Standby, we’d love to hear it!